Notes taken from this workshop: Patterns for Continuous Delivery, Reactive, High Availability, DevOps & Cloud Native Open Source with NetflixOSS
The workshop was essentially a series of presentations by Adrian Cockcroft and Ben Christensen
Notes taken from this workshop: Patterns for Continuous Delivery, Reactive, High Availability, DevOps & Cloud Native Open Source with NetflixOSS
The workshop was essentially a series of presentations by Adrian Cockcroft and Ben Christensen
Slides
- Adrian's Slides:
- Ben's Slides:
- Application Resilience Engineering and Operations at Netflix [pdf] <-- this is the closest set of slides to the workshop content
- Other slides on SpeakerDeck
- Adrian's Slides:
- Ben's Slides:
- Application Resilience Engineering and Operations at Netflix [pdf] <-- this is the closest set of slides to the workshop content
- Other slides on SpeakerDeck
Diagrams
NetFlix Architecture Diagrams

















Cloud at Scale
Adrian Cockcroft
Adrian Cockcroft
Time to market vs Quality
- Aggressively go out and assume that things are broken
- e.g. Land grab, market disruption, web services
- Default assumptions
- Always shipping code that is broken
- Hardware is broken
- Operationally defensive
- Aggressively go out and assume that things are broken
- e.g. Land grab, market disruption, web services
- Default assumptions
- Always shipping code that is broken
- Hardware is broken
- Operationally defensive
Need ability to see in realtime
- Small change, quick to fix
- Able to revert
- Small change, quick to fix
- Able to revert
Cloud Native – a new engineering challenge
- Construct highly agile and hilgly available service from ephemeral and assumjed broken components
- Construct highly agile and hilgly available service from ephemeral and assumjed broken components
Inspiration
- · Release it
- · Bulkhead & circuit-breaker
- · Thinking in Systems – Donella H Meadows
- · Chaotic system
- · Order from Chaos
- · Emergent behaviour is that it shows movies
- · Right feedback loops
- · Not about software – about building feedback loops & rules around things so that they’re stable & predictable
- · Looks like an ants nest – chaotic but order is an emergent property
- · Anti-fragile
- · Drift Into Failure – Sidney Decker
- · Aircraft industry lessons
- · Ways to avoid
- · Latent failures
- · Netflix outages are unique
- · Byzantine
- · Have enough margin
- · Gradually take fat out of the system – drop dead if you miss a meal
- · Everything is obvious – Duncan J. Watts
- · Avoid untrained people rushing in a pushing buttons
- · The REST API Design Handbook
- · 100s of microservices
- · Short book ranting on bad apis
- · Dell Cloud something
- · $3
- · “REST in Practice” also good
- · Continuous Delivery
- · Cloudonomics
- · Cost model
- · Detailed analysis of cloud costs and how it fits together
- · Phoenix Project
- · Release it
- · Bulkhead & circuit-breaker
- · Thinking in Systems – Donella H Meadows
- · Chaotic system
- · Order from Chaos
- · Emergent behaviour is that it shows movies
- · Right feedback loops
- · Not about software – about building feedback loops & rules around things so that they’re stable & predictable
- · Looks like an ants nest – chaotic but order is an emergent property
- · Anti-fragile
- · Drift Into Failure – Sidney Decker
- · Aircraft industry lessons
- · Ways to avoid
- · Latent failures
- · Netflix outages are unique
- · Byzantine
- · Have enough margin
- · Gradually take fat out of the system – drop dead if you miss a meal
- · Everything is obvious – Duncan J. Watts
- · Avoid untrained people rushing in a pushing buttons
- · The REST API Design Handbook
- · 100s of microservices
- · Short book ranting on bad apis
- · Dell Cloud something
- · $3
- · “REST in Practice” also good
- · Continuous Delivery
- · Cloudonomics
- · Cost model
- · Detailed analysis of cloud costs and how it fits together
- · Phoenix Project
How to get to Cloud Native
- Freedom and Responsibility for Developers
- Decentralize and Automate Ops Activities
- Integrate DevOps into the Business Organization
- Re-org!
- Freedom and Responsibility for Developers
- Decentralize and Automate Ops Activities
- Integrate DevOps into the Business Organization
- Re-org!
Four transitions
- Management: Integrated Roles in a Single Organization
- Business, Development, Operations -> BusDevOps
- Developers: Denormalized Data – NoSQL
- Decentralized, scalable, available, polyglot
- Hardest thing to get everyone’s head around
- Don't really need transactions anyway
- Data checkers run around checking bits of data have correct ids and “foreign keys”
- No such thing as consistency
- Paranoia covered by backups
- Responsibility from Ops to Dev: Continuous Delivery
- Decentralized small daily production updates
- Push to prod end of every day
- Responsibility from Ops to Dev: Agile Infrastructure - Cloud
- Hardware in minutes, provisioned directly by developers
- Management: Integrated Roles in a Single Organization
- Business, Development, Operations -> BusDevOps
- Developers: Denormalized Data – NoSQL
- Decentralized, scalable, available, polyglot
- Hardest thing to get everyone’s head around
- Don't really need transactions anyway
- Data checkers run around checking bits of data have correct ids and “foreign keys”
- No such thing as consistency
- Paranoia covered by backups
- Responsibility from Ops to Dev: Continuous Delivery
- Decentralized small daily production updates
- Push to prod end of every day
- Responsibility from Ops to Dev: Agile Infrastructure - Cloud
- Hardware in minutes, provisioned directly by developers
Fitting into public scale
· 1,000 – 100,000 instances is ideal for AWS
· 500k instances 3 years ago, 5m today
· 1,000 – 100,000 instances is ideal for AWS
· 500k instances 3 years ago, 5m today
Netflix don’t use AWS for
Open Connect Appliance Hardware - Netflix Open Source Content Delivery Service
· 5 engineers got together for 4 months and built their own hardware
· Build it themselves
· Give them away
· $15k
· Pre-loaded static content
· Nginx, Bind, Bird bind library
· BSD
· UFS+ filesystem
· Unmount disk if it fails, lower capacity – no striping
· Hot content on SSD
· 5 engineers got together for 4 months and built their own hardware
· Build it themselves
· Give them away
· $15k
· Pre-loaded static content
· Nginx, Bind, Bird bind library
· BSD
· UFS+ filesystem
· Unmount disk if it fails, lower capacity – no striping
· Hot content on SSD
DNS Service
- Route53 missing too many features
- Amazon will clean up in the DNS market when they finish Route53
- Route53 missing too many features
- Amazon will clean up in the DNS market when they finish Route53
Escaping the Death Spiral
- Get out of the way of innovation
- Process reduction - aggressively
- Hardware: Best of breed, by the hour
- If don’t like it – get rid of it
- Choices based on scale
- E.g. Big scale = US East Region
- Build your own DNS
- Get out of the way of innovation
- Process reduction - aggressively
- Hardware: Best of breed, by the hour
- If don’t like it – get rid of it
- Choices based on scale
- E.g. Big scale = US East Region
- Build your own DNS
Getting to Cloud Native
Getting started with NetflixOSS Step by Step
- Set up AWS Accounts to get the foundation in place
- Security and access management setup
- Account Management: Asgard to deploy & Ice for cost monitoring
- Build Tools: Aminator to automate baking AMIs
- Service Registry and Searchable Account History: Eureka & Edda
- Configuration Management: Archaius dynamic property system
- Data storage: Cassandra, Astyanax, Priam, EVCache
- Dynamic traffic routing: Denominator, Zuul, Ribbon, Karyon
- Availability: Simian Army (Chaos Monkey), Hystrix, Turbine
- Developer productivity: Blitz4J, GCViz, Pytheas, RxJava
- Big Data: Genie for Hadoop PaaS, Lipstick visualizer for Pig, Suro (logging pipeline)
- Sample Apps to get started: RSS Reader, ACME Air (IBM), FluxCapacitor
- Set up AWS Accounts to get the foundation in place
- Security and access management setup
- Account Management: Asgard to deploy & Ice for cost monitoring
- Build Tools: Aminator to automate baking AMIs
- Service Registry and Searchable Account History: Eureka & Edda
- Configuration Management: Archaius dynamic property system
- Data storage: Cassandra, Astyanax, Priam, EVCache
- Dynamic traffic routing: Denominator, Zuul, Ribbon, Karyon
- Availability: Simian Army (Chaos Monkey), Hystrix, Turbine
- Developer productivity: Blitz4J, GCViz, Pytheas, RxJava
- Big Data: Genie for Hadoop PaaS, Lipstick visualizer for Pig, Suro (logging pipeline)
- Sample Apps to get started: RSS Reader, ACME Air (IBM), FluxCapacitor
Flow of Code & Data between AWS Accounts
- Auditable Account: Code with dollar signs goes into this account
- Archive Account
- Test account gets refreshed every weekend of all schemas/data from Prod
- Trashes test data
- Confidential data is encrypted at rest
- Tokenise sensitive data
- Cloud LDAP gives you access to Production Account
- Auditable Account is different LDAP group, need a reason to access it
- Vault account needs a background check
- Higher security apps
- Monitoring systems inside
- Smaller and smaller for higher security
- Hyperguard & cloudpassage
- Cloud security architect used to be a PCI auditor – could talk to auditors at their level
- Had to educate auditors
- Archive Account
- Versioned
- Can’t delete anything from archive account
- Delete old copies
- PGP encrypted backup copies to Google, last resort DR copy
- Immutable logs from Cassandra for full history
- Auditable Account: Code with dollar signs goes into this account
- Archive Account
- Test account gets refreshed every weekend of all schemas/data from Prod
- Trashes test data
- Confidential data is encrypted at rest
- Tokenise sensitive data
- Cloud LDAP gives you access to Production Account
- Auditable Account is different LDAP group, need a reason to access it
- Vault account needs a background check
- Higher security apps
- Monitoring systems inside
- Smaller and smaller for higher security
- Hyperguard & cloudpassage
- Cloud security architect used to be a PCI auditor – could talk to auditors at their level
- Had to educate auditors
- Archive Account
- Versioned
- Can’t delete anything from archive account
- Delete old copies
- PGP encrypted backup copies to Google, last resort DR copy
- Immutable logs from Cassandra for full history
Account Security
- Protect Accounts
- Two factor authentication for primary login
- Delegated Minimum Privilege
- Create IAM roles for everything
- Fine-grained – as-needs basis
- Security Groups
- Control who can call your services
- Every service has a security group with the same name
- Have to be in the group to be able to call the service
- Managing service ingress permission = customer base
- Can ignore services not in my security group
- Superset of interactions
- Not all customers call the service
- Call tree is monitored through other means
- Protect Accounts
- Two factor authentication for primary login
- Delegated Minimum Privilege
- Create IAM roles for everything
- Fine-grained – as-needs basis
- Security Groups
- Control who can call your services
- Every service has a security group with the same name
- Have to be in the group to be able to call the service
- Managing service ingress permission = customer base
- Can ignore services not in my security group
- Superset of interactions
- Not all customers call the service
- Call tree is monitored through other means
Cloud Access Control
- SSH Bastion
- Sumo Logic
- Ssh sudo bastion
- Can’t ssh between instances – have to go via bastion which wraps sudo with audit logs
- Login is yourself
- oq ssh wrapper into machine root or login as regular e.g. default is “dal-prod”
- Your user doesn’t exist on machines
- E.g. “dal-prod” is 105, “www-prod” is 106
- Dont’ run anything as root
- Register of accounts – Asgard
- Failure modes
- Datacenter dependency
- 2 copies of bastion host
- Homedir is the same
- Scripts that trample in through bastion – bad idea
- NFS server died lost all shares
- Datacenters keep breaking your cloud
- 1 service per host
- AWS firewall layer is dodgy – creates variance in the network

- SSH Bastion
- Sumo Logic
- Ssh sudo bastion
- Can’t ssh between instances – have to go via bastion which wraps sudo with audit logs
- Login is yourself
- oq ssh wrapper into machine root or login as regular e.g. default is “dal-prod”
- Your user doesn’t exist on machines
- E.g. “dal-prod” is 105, “www-prod” is 106
- Dont’ run anything as root
- Register of accounts – Asgard
- Failure modes
- Datacenter dependency
- 2 copies of bastion host
- Homedir is the same
- Scripts that trample in through bastion – bad idea
- NFS server died lost all shares
- Datacenters keep breaking your cloud
- 1 service per host
- AWS firewall layer is dodgy – creates variance in the network

Fast Start AMIs
- AWS Answers
- 1 Asgard copy per account
- AWS Answers
- 1 Asgard copy per account
Stateless services talk to memcache/Cassandra/RDS
No SQL queries – all REST calls to webservices
Asgard
- Grails app
- All UI endpoints can be read by adding .json
- Grails app
- All UI endpoints can be read by adding .json
Eureka

Edda
- Timestamped delta cache of service status mongodb/ES back-end
- Searchable history of AWS instance, deployment version, etc changes
- Every 1min
- Janitor monkey cleans up
- Eucalyptus = AWS-compatible private cloud – lets you see more underlying infra data e.g. switches
- Cloud Trail give you record of calls made to configure cloud and who made them
- E.g. Machines that blew up last week no longer exist
- Very powerfull for security / auditing
- CMDBs in data center don’t work – this actually works – strong assertions

- Timestamped delta cache of service status mongodb/ES back-end
- Searchable history of AWS instance, deployment version, etc changes
- Every 1min
- Janitor monkey cleans up
- Eucalyptus = AWS-compatible private cloud – lets you see more underlying infra data e.g. switches
- Cloud Trail give you record of calls made to configure cloud and who made them
- E.g. Machines that blew up last week no longer exist
- Very powerfull for security / auditing
- CMDBs in data center don’t work – this actually works – strong assertions

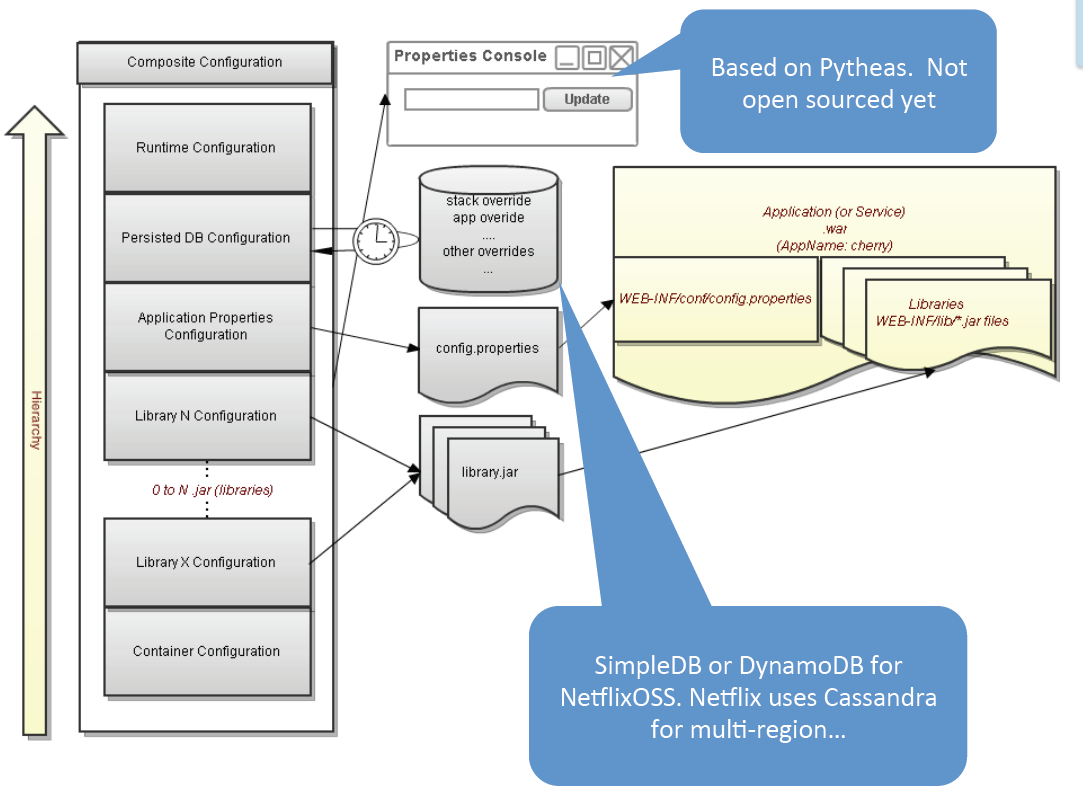
Archaius
- Property Console
- Not OS yet
- Based on Pytheas
- Property Console
- Not OS yet
- Based on Pytheas
Archaius Library Config Mgmt
- Hierarchy of properties
- Changes are logged with Chronos

- Hierarchy of properties
- Changes are logged with Chronos

Astyanax
- A6x
- Son of Hector (brother of Cassandra)
- Recipes
- Patterns to solve common problems
- A6x
- Son of Hector (brother of Cassandra)
- Recipes
- Patterns to solve common problems
EVCache
- Eccentric (Ephemeral) Volatile Cache
- Memcache in each zone
- “Dynomite” Cassandra-like layer above memcache
- Prium-like sidecar exposes metrics over JMX

- Eccentric (Ephemeral) Volatile Cache
- Memcache in each zone
- “Dynomite” Cassandra-like layer above memcache
- Prium-like sidecar exposes metrics over JMX

Routing Customers to Code
- Denominator: DNS for multi-region availability
- Manage traffic via multiple DNS providers with Java code (or command-line)
- Talks to Ultra, Dyn, Route53, OpenStack
- Pluggable
- Ultra does Geo split (partitioning)
- Switch to Dyn if Ultra breaks
- Route53 does switching
- If a Region goes down denominator switches LB at Route53 layer
- 50 endpoints
- Talks to Zuul API Router
- Zuul – Smart routing
- Groovy filters update every 30s
- E.g. block Russian addresses
- Similar to masher, apigee
- Ribbon
- Internal LB
- Wrapper around HTTP Client
- Round robin connections
- Backed by Eureka
- Karyon – common server container
- Hello world
- Embedded status page console
- Machine readable
- Enables conformity monkey
- E.g. Reject if it has versions of libraries

- Denominator: DNS for multi-region availability
- Manage traffic via multiple DNS providers with Java code (or command-line)
- Talks to Ultra, Dyn, Route53, OpenStack
- Pluggable
- Ultra does Geo split (partitioning)
- Switch to Dyn if Ultra breaks
- Route53 does switching
- If a Region goes down denominator switches LB at Route53 layer
- 50 endpoints
- Talks to Zuul API Router
- Zuul – Smart routing
- Groovy filters update every 30s
- E.g. block Russian addresses
- Similar to masher, apigee
- Ribbon
- Internal LB
- Wrapper around HTTP Client
- Round robin connections
- Backed by Eureka
- Karyon – common server container
- Hello world
- Embedded status page console
- Machine readable
- Enables conformity monkey
- E.g. Reject if it has versions of libraries

Availability
- Torture Monkeys – barrel fill of monkeys
- Block DNS
- Fill up root disk
- Unmount ebs
- Block access to ec2 apis
- CPU busy
- Killing all Java processes
- Torture Monkeys – barrel fill of monkeys
- Block DNS
- Fill up root disk
- Unmount ebs
- Block access to ec2 apis
- CPU busy
- Killing all Java processes
Developer productivity
- Blitz4J – non-blocking logging
- GCViz
- Runs off log files
- Pytheas – OSS based tooling framework
- Powerful - Just a little code in the right place
- Scaffolding
- Guice, Jersey, FreeMarker, JQuery, DataTabler, D3, Bootstrap
- Blitz4J – non-blocking logging
- GCViz
- Runs off log files
- Pytheas – OSS based tooling framework
- Powerful - Just a little code in the right place
- Scaffolding
- Guice, Jersey, FreeMarker, JQuery, DataTabler, D3, Bootstrap
BigData & Analytics
- Genie - Hadoop jobs
- Complex Processing of S3 data
- Lipstick – visualisation for Pig queries
- Suro – event logging pipeline
- Feeds Kafka, Storm, Druid
- Alerting
- 80-100bn events/day
- Genie - Hadoop jobs
- Complex Processing of S3 data
- Lipstick – visualisation for Pig queries
- Suro – event logging pipeline
- Feeds Kafka, Storm, Druid
- Alerting
- 80-100bn events/day
Sample App – RSS Reader
Glisten – Workflow DSL – Amazon Simple Workflow
Scale & Resilience (Resilient API Patterns)
Ben Christensen
Ben Christensen
Constraints
- Client libraries
- Service provides a client library
- To enable speed of iteration
- While we want resources integration, procedure integration works out faster
- Mixed Environment
- Polyglot
- Client libraries
- Service provides a client library
- To enable speed of iteration
- While we want resources integration, procedure integration works out faster
- Mixed Environment
- Polyglot
Client libraries
- Deal with Logic, Serialisation, Network Request, Deserialisation, Logic
- Bulkheading to prevent socket timeouts
- Limit the blast radius
- Hystrix
- Tryable Semaphore
- E.g. 3-4 threads will do 50rps
- Cap at 10 – don’t reject until hit 10 threads
- Reject in non-blocking way – queue
- Fast-fail shared load or fall-back
- Thread pool
- Size of thread pool + queue size (typically 0)
- Slight overhead for extra threads
- Gives extra safety of being able to release the blocking user instead of waiting on connection
- Enables interrupting blocking threadHystrix Command Object pattern
- Synchronous execute
- Asynchronously
- Circuit open? Rate limit?
- Failure options
- Fail fast instead of backing up – backed up systems do not recover quickly
- Shed load so can start processing immediately
- Fail silent
- Netflix shouldn’t fail for customer just because Netflix can’t talk to Facebook
- Static fallback
- Instead of turning feature off... turn it to default state (true, DEFAULT_OBJECT)
- Fail open instead of failing closed
- Stubbed fallback
- Stub parameters with defaults if don’t know
- Fallback via network
- Try something else based on similar data
- Hystrix
- Each app cluster has a page of Circuit Breakers
- Shows last 10s
- Links to historical data
- Different decisions about




- Deal with Logic, Serialisation, Network Request, Deserialisation, Logic
- Bulkheading to prevent socket timeouts
- Limit the blast radius
- Hystrix
- Tryable Semaphore
- E.g. 3-4 threads will do 50rps
- Cap at 10 – don’t reject until hit 10 threads
- Reject in non-blocking way – queue
- Fast-fail shared load or fall-back
- Thread pool
- Size of thread pool + queue size (typically 0)
- Slight overhead for extra threads
- Gives extra safety of being able to release the blocking user instead of waiting on connection
- Enables interrupting blocking threadHystrix Command Object pattern
- Synchronous execute
- Asynchronously
- Circuit open? Rate limit?
- Failure options
- Fail fast instead of backing up – backed up systems do not recover quickly
- Shed load so can start processing immediately
- Fail silent
- Netflix shouldn’t fail for customer just because Netflix can’t talk to Facebook
- Static fallback
- Instead of turning feature off... turn it to default state (true, DEFAULT_OBJECT)
- Fail open instead of failing closed
- Stubbed fallback
- Stub parameters with defaults if don’t know
- Fallback via network
- Try something else based on similar data
- Fail fast instead of backing up – backed up systems do not recover quickly
- Hystrix
- Each app cluster has a page of Circuit Breakers
- Shows last 10s
- Links to historical data
- Different decisions about




Deployment
- Zuul Routing Layer
- Replaces ELBs + Commercial proxy layer
- Hated it: 1-2 days to make simple rule change
- Simple Pre and Post filters on HTTP Request/Response
- Can add & remove filters at runtime
- Routing changes
- Use Cases
- Want to know all logs for particular User-id across entire fleet – via Turbine
- Canary vs Baseline
- Launch 2 clusters
- Run through 1 peak cycle
- Squeeze Testing
- Impossible with out Zuul
- RPS on a particular instance (Math in a filter)
- Increment in 5rps increments
- Test every binary to see what it’s breaking point is
- How many machines will we need in prod?
- Is this change inefficient?
- Auto-scaling parameters?
- Test can’t come close to prod load – different load
- Really hard to simulate true load, cache hits
- Don’t bother with Load Tests
- Squeeze tests as part of prod
- Acceptable break?
- Client will typically retry (or get a “Try again” prompt)
- Retry will probably hit a different box (out of 100s)
- Rules are tested in a Zuul canary
- Prod Zuul cluster – small Zuul cluster
- Activate on main cluster after tested
- Coalmine
- Long-term canary cluster
- Java agents with byte code manipulation
- Intercept network traffic
- Watch a particular binary
- Raise alarm if see network traffic not isolated by Hystrix
- E.g. Someone Flips code Not correctly isolated
- Look in Chronous to see what was changed
- Production
- Scryer – predicitive auto-scaling
- Uses last 4 weeks for any particular day of week
- Creates an auto-scaling plan for ASG
- Move min-floor up and down, leave max high
- 5% buffer better than 10-20% buffer for reactive
- Still have reactive plan to kick in for a safety net (e.g. Snow day)
- Will keep scaling up even if not receiving predicted traffic – avoids outage when traffic suddenly comes back online
- Zuul Routing Layer
- Replaces ELBs + Commercial proxy layer
- Hated it: 1-2 days to make simple rule change
- Replaces ELBs + Commercial proxy layer
- Simple Pre and Post filters on HTTP Request/Response
- Can add & remove filters at runtime
- Routing changes
- Use Cases
- Want to know all logs for particular User-id across entire fleet – via Turbine
- Canary vs Baseline
- Launch 2 clusters
- Run through 1 peak cycle
- Squeeze Testing
- Impossible with out Zuul
- RPS on a particular instance (Math in a filter)
- Increment in 5rps increments
- Test every binary to see what it’s breaking point is
- How many machines will we need in prod?
- Is this change inefficient?
- Auto-scaling parameters?
- Test can’t come close to prod load – different load
- Really hard to simulate true load, cache hits
- Don’t bother with Load Tests
- Squeeze tests as part of prod
- Acceptable break?
- Client will typically retry (or get a “Try again” prompt)
- Retry will probably hit a different box (out of 100s)
- Rules are tested in a Zuul canary
- Prod Zuul cluster – small Zuul cluster
- Activate on main cluster after tested
- Coalmine
- Long-term canary cluster
- Java agents with byte code manipulation
- Intercept network traffic
- Watch a particular binary
- Raise alarm if see network traffic not isolated by Hystrix
- E.g. Someone Flips code Not correctly isolated
- Look in Chronous to see what was changed
- Production
- Scryer – predicitive auto-scaling
- Uses last 4 weeks for any particular day of week
- Creates an auto-scaling plan for ASG
- Move min-floor up and down, leave max high
- 5% buffer better than 10-20% buffer for reactive
- Still have reactive plan to kick in for a safety net (e.g. Snow day)
- Will keep scaling up even if not receiving predicted traffic – avoids outage when traffic suddenly comes back online
Testing
- Testers do manual testing on UI
- Engineers have to make their stuff work
- Code reviews are up to each team culture
- Risky request feedback on pull request
- Canary
- If significant degradation – canary test fails
- Integration testing?
- Smoke testing does a lot of the service testing
- Expected data testing “prod” branch is latest dependency integration
- Nightly build
- If fails, integration guys won’t promote it
- Not scientific
- A/B Testing – See Jason Brown presentation
- Testers do manual testing on UI
- Engineers have to make their stuff work
- Code reviews are up to each team culture
- Risky request feedback on pull request
- Canary
- If significant degradation – canary test fails
- Integration testing?
- Smoke testing does a lot of the service testing
- Expected data testing “prod” branch is latest dependency integration
- Nightly build
- If fails, integration guys won’t promote it
- Not scientific
- A/B Testing – See Jason Brown presentation
Migrating Data Changes
- Don’t make breaking changes
- Never attempt to synchronise releases
- Wait until all consumers are up-to-date
- Client library facade
- Don’t make breaking changes
- Never attempt to synchronise releases
- Wait until all consumers are up-to-date
- Client library facade
Other Notes
- Build compatibility into client library
- Client library boils down to just fallback decisions in Hystrix circuit breakers
- Working on static analysis to check
- Keep track of which clients call which endpoints – know who’s affected by changes
- Build compatibility into client library
- Client library boils down to just fallback decisions in Hystrix circuit breakers
- Working on static analysis to check
- Keep track of which clients call which endpoints – know who’s affected by changes
Performance & Innovation
Ben Christensen
Ben Christensen
Suro Event Pipeline
- Cloud native, dynamic, configurable offline and realtime data sinks
- Open-sourced yesterday
- S3 demultiplexing -> Hadoop -> BI
- Kafka -> Druid and ES
- Druid = realtime data cube
- Not event processing
- Counting on multiple dimensions
- Can plug Storm into Kafka for event processing
- ES for searching events
- Cloud native, dynamic, configurable offline and realtime data sinks
- Open-sourced yesterday
- S3 demultiplexing -> Hadoop -> BI
- Kafka -> Druid and ES
- Druid = realtime data cube
- Not event processing
- Counting on multiple dimensions
- Can plug Storm into Kafka for event processing
- ES for searching events
Availability
Adrian Cockcroft
Adrian Cockcroft
Incident management
- PagerDuty alerts are automated
- Incident creation is not automated
- PagerDuty alerts are automated
- Incident creation is not automated
Cassandra at Scale
- Boundary.com – network flow analysis
- Small number of nodes for free
- Boundary.com – network flow analysis
- Small number of nodes for free
Failure Modes and Effects

Auto-scaling saves up to 70%
Janitor monkey
- Uses Edda to find things not used
- Uses Edda to find things not used
Compare TCO
- Place
- Power
- Pipes
- People
- Patterns
- Managing, overhead, tooling
- Jevons Paradox
- If you make something more efficient people will consume more of it more people will use it – more than the efficiency gains
- Amazon incent their sales reps to help you save money
- Place
- Power
- Pipes
- People
- Patterns
- Managing, overhead, tooling
- Jevons Paradox
- If you make something more efficient people will consume more of it more people will use it – more than the efficiency gains
- Amazon incent their sales reps to help you save money
Size for the amount of RAM you need then scale horizontally
Bonus notes from sidechat about "Consumer-Driven Contracts" with Sam Newman
Recommended Resources for testing Consumer-Driven Contracts?
- Anything by Ian Robinson (“Rest in practice” author)
- http://www.infoq.com/articles/consumer-driven-contracts
- Anything by Ian Robinson (“Rest in practice” author)
- http://www.infoq.com/articles/consumer-driven-contracts
Other Tips
- Rely more on monitoring in prod
- Synthetic Transactions
- A/B Testing
- Releasing apps together is the wrong way to go
- It’s a smell that your apps are becoming tightly coupled
- Ends up tying you back to a monolithic structure
- Rely more on monitoring in prod
- Synthetic Transactions
- A/B Testing
- Releasing apps together is the wrong way to go
- It’s a smell that your apps are becoming tightly coupled
- Ends up tying you back to a monolithic structure